文献解读 | 一篇IF=17分的预测模型文章解读
今天要给大家解读的是一篇预测模型文章,一个回顾性研究仅用243例样本量就能发IF=17的高分杂志,到底有什么过人之处呢?下面就让我们仔细分析一下吧。
这篇文章的题目是:A prediction nomogram for neonatal acute respiratory distress syndrome in late-preterm infants and full-term infants: A retrospective study .翻译成中文是:晚期早产儿和足月新生儿急性呼吸窘迫综合征的预测图:一项回顾性研究。
首先还是老规矩,用PICOS原则来拆解这篇文章:研究人群P是晚期早产儿和足月新生儿,I&C是预测指标,观察结局O是急性呼吸窘迫综合征(ARDS),研究类型S是一项回顾性研究,文章结构是一篇预测模型。
经过PICOS拆解,就大概知道这是一项通过回顾性的收集晚期早产儿和足月新生儿的基线指标,来预测发生ARDS概率的研究。
接下来我们通过文章的图表来拆解思路:
图1:Flow chart for patient selection
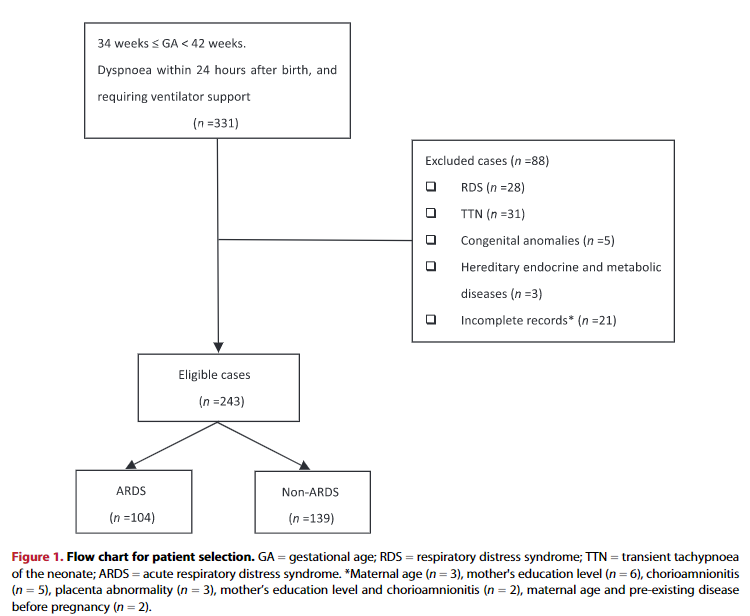
研究流程图几乎是SCI文章必备的图1,通过这张图可以清楚地知道这项研究一共筛选了331例患者,符合纳排标准的是243例,最后发生了ARDS的是104例,未发生ARDS139例。
表1 Baseline characteristics of all patients in the training cohort and validation cohort
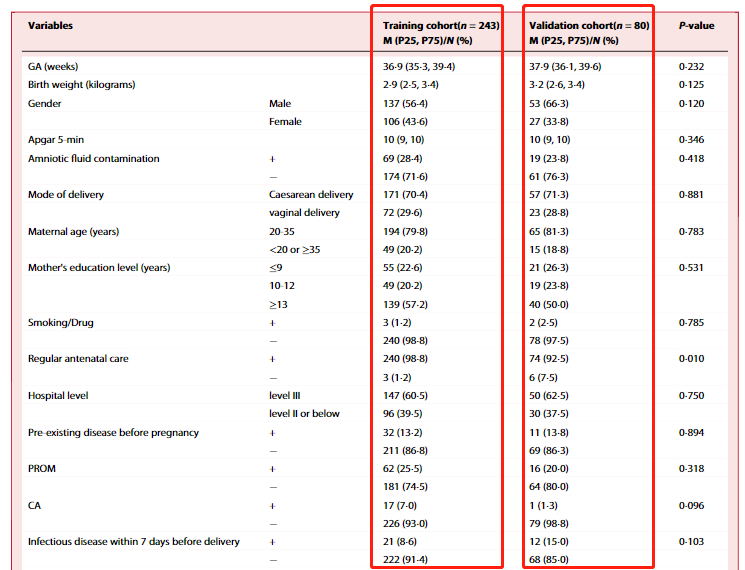
从表一可以看出,这项研究将人群分成了两个队列,一个是训练队列training cohort,一个是验证队列validation cohort,将这两个队列的基线特征分别进行了描述,并且进行了对比,表示两个队列之间的基线无差异。
这点非常值得我们借鉴,如果你也想开展一项预测模型研究,也可以构建两个队列,训练队列用于筛选预测因子建立预测模型,验证队列用来验证评估模型。模型验证是一个良好的预测模型建立过程中不可或缺的步骤,验证方法包括内部验证和外部验证。两者的主要区别在于前者的训练集和验证集数据来自同一个数据集,而后者的训练集和验证集则是来自不同的数据集。
表2 Multivariate logistic regression analyses for screen predictors
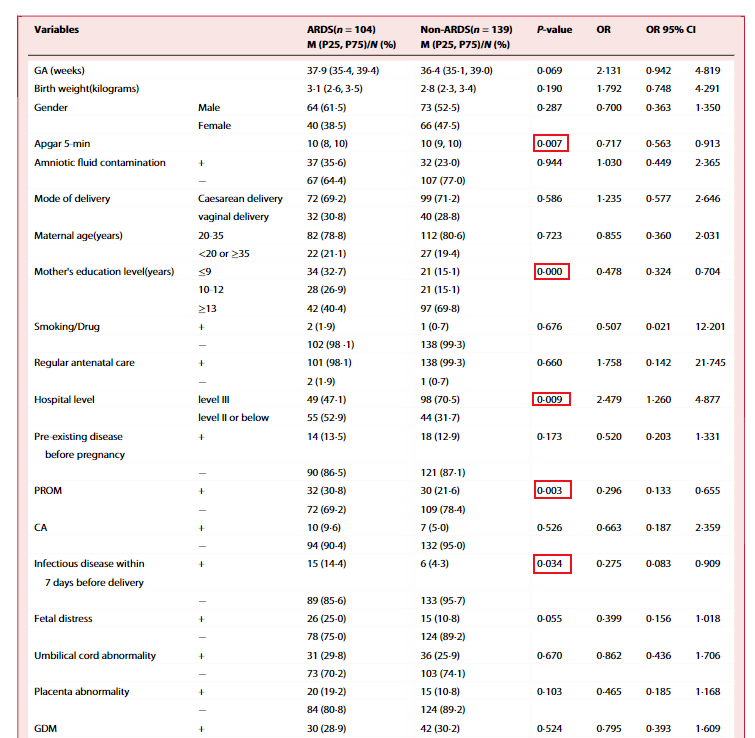
表二用多元回归分析来筛选预测因子,对发生和未发生ARDS的人群特征分别进行描述统计,并展示了回归分析的OR值,以P<0.05为界限,筛选出5个预测因子。
图2 Nomogram for the perinatal prediction of neonatal ARDS.
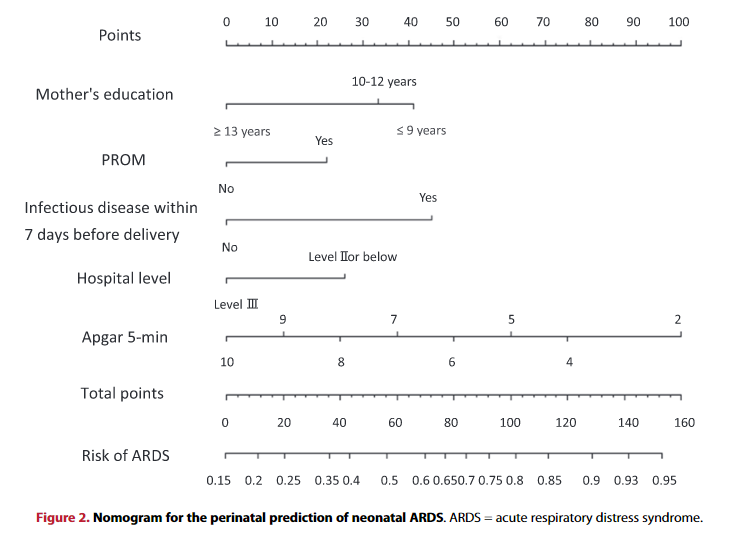
图2是本篇文章的重点,用表2筛选出的5个因素建立logistic回归模型,并绘制列线图,本篇文章的结果一目了然。
可能有些小伙伴对于列线图还不是很了解,列线图是根据模型中各个影响因素对结局变量的贡献程度(回归系数的大小),给每个影响因素的取值水平或取值范围进行赋分,然后再将各个评分相加得到总评分,最后通过总评分与结局事件发生概率之间的函数转换关系,从而计算出该个体结局事件发生的预测概率。简单来说就是一个可视化的评分卡。
到这里可能大多数读者都认为本篇文章的数据分析结束了,但是记得我们前面讲过,模型的评估是预测模型必不可少的步骤,所以作者接下来对建立的这个预测模型进行了评估和验证。
图3 ROC curves
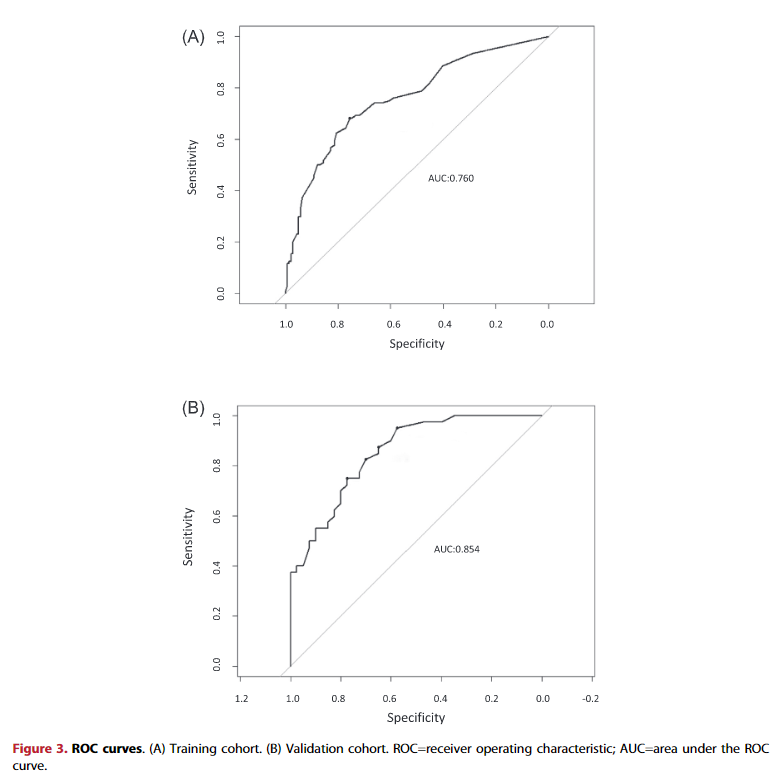
图4 Calibration curve
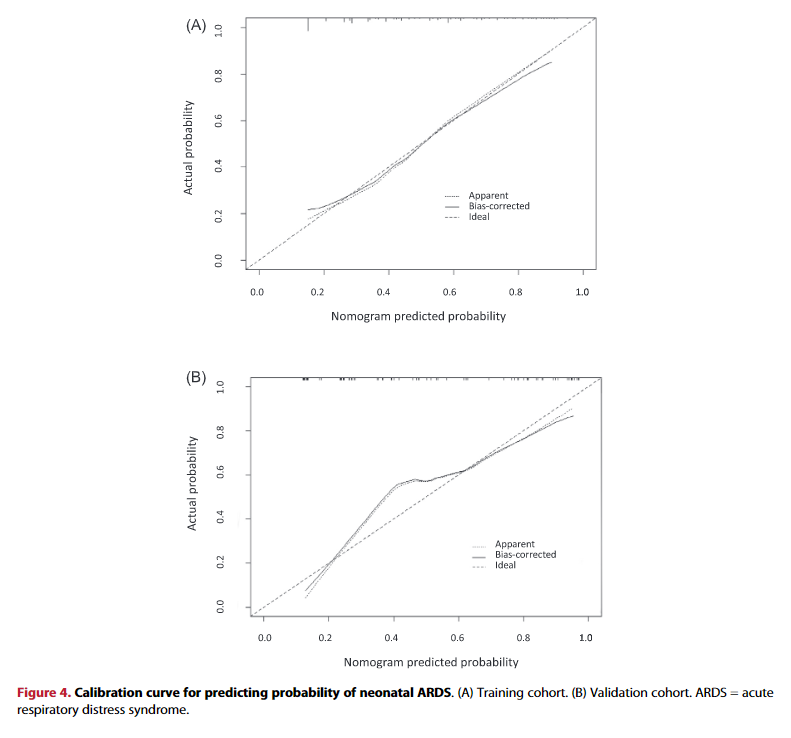
图3和图4分别通过区分度和校准度来对预测模型进行了评估和验证。
图3展示了训练队列和验证队列的ROC曲线,AUC值分别是0.760和0.854,说明预测模型的区分度较好;图4用校准曲线来评估模型的校准度,校准曲线反映模型预测个体发生结局事件的概率和真实概率的一致程度,越接近对角线,预测结果更理想。
总结
以上就是本篇文章的所有分析过程,其实整个分析思路非常简单,最后我们来总结一下本篇研究的预测模型构建思路吧~
1.建立研究队列和验证队列。
2.筛选预测因子。
3.构建回归模型。
4.评估模型。
5.验证模型。
这篇文章虽然是一篇回顾性研究,并且样本量不算太大,但是亮点在于建立了验证队列,以及对于模型的评估做的比较深入,整篇文章的分析思路很经典,没有什么特殊的分析方法,很值得参考借鉴。
*本文系转载,如涉及版权等问题,请联系我们以便处理
 电话:400-9933-062
电话:400-9933-062 电子邮箱:business@wykt.com
电子邮箱:business@wykt.com

